🚀 Ready to Finally Upgrade from messy ML notebooks? Setup to Shipping Challenge
There's a big difference between writing a data science notebook with sklearn pipelines and actually shipping ML code so it can run reliably and not on your laptop 😶 In the past 2 years in my job I have learned a lot about deployments in real life (not at FAANG) and will put them together in this short challenge format this month.
You can start anytime this month, go at your own pace, and by the end you’ll have:
- A clean repo structure ready for any new ML project
- Modular code with proper imports ready to be extended and tested
- A config system using Pydantic (goodbye hard-coded paths)
- Basic MLflow tracking for experiments
- A Python package you can deploy to the cloud (Databricks example included)
Here's what we are doing this month (we, if you are joining me, otherwise just me 😔)
📆 4 weeks of short, weekly tasks (start anytime!)
✅ Get the previous week’s “solution” in each email
🏗️ End with a reusable ML project blueprint
💰 Free for newsletter readers this month
I’m doing this because I want a ready-to-use ML project blueprint for myself - something I can copy for every new proof of concept at work or in side projects. You’ll have the same: a starting point with all the best practices built in, that you can adjust in whatever way needed.
Week-by-Week Outline
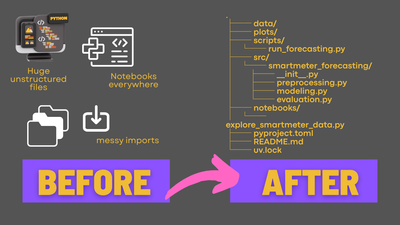
Week 1: Your ML Repo Starter Kit: src Layout, uv venv, GitHub Push
Week 2: How to Validate Config YAML in Machine Learning Pipelines
Your Week 1 Task (Start Now) 💪🏻
Create the best version of a folder structure for a new ML project that you can think of - no code yet, just the scaffolding.
Need some ideas?
- The directory structure from the Cookiecutter Data Science Project
- My recent post on adding a
src/folder and why you would do that
You can also use my guide on how I use uv, but that's already almost cheating ⚠️
No spam, no sharing to third party. Only you and me.




Member discussion